Tracking FPGA design build metrics
…with low infrastructure footprint

For my latest FPGA toy project, I was looking for a way to have an overview of builds with performance metrics – fmax and resource usage, but also results of simulation and benchmarks.
GitLab CI has a convenient feature whereby one can specify a regular expression to extract test coverage from CI logs, and this value is then displayed on the job list page. Unfortunately it does not offer any flexibility beyond that.
Despite searching far and wide, I didn’t find any satisfactory solution (at least not for free), so I set out to build my own.
The rough idea was the following:
- collect key metrics from CI jobs:
- timing results
- resource usage
- test results under simulation
- benchmarks under simulation
- accumulate data across builds
- present in a spreadsheet for easy viewing
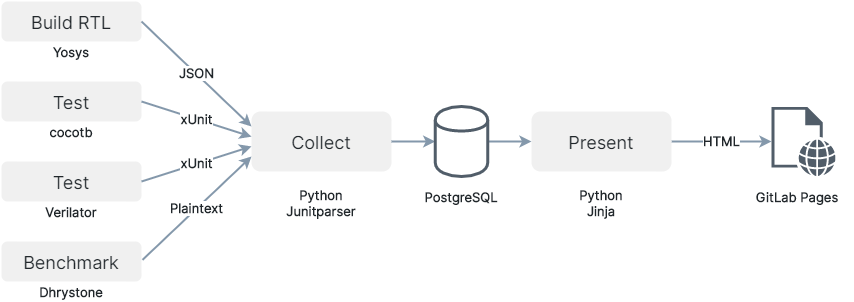
Since I am already quite invested in GitLab CI, I wanted to maximally reuse the facilities it provides. However, to accumulate data across many builds, I still needed some kind of database. I opted for PostgreSQL, motivated by the existence of Supabase, which provides a 500 MB cloud-hosted database for free. It doesn’t really matter, a private MariaDB or some NoSQL solution would do the job as well. The only requirement is reachability from the CI runners.
The next question was one of the database schema. I decided to harcode only a few very general columns which might need to be indexed later, for purposes of filtering and sorting:
- commit hash & title
- timestamps of commit + pipeline
- CI pipeline URL
- branch name
The rest of the build data is shoved into a JSON object to allow maximum flexibility and easy schema evolution.
To present the data, a final CI job generates a static, self-contained HTML page and deploys it via GitLab Pages. Simple!
Implementation
Let’s take a walk through the code now.
DB schema
We start by creating a table. (Recall that public is the default schema in a new PostgreSQL database.)
CREATE TABLE public.builds (
id serial NOT NULL,
pipeline_timestamp timestamp(0) NOT NULL,
pipeline_url varchar NOT NULL,
branch varchar NOT NULL,
commit_sha1 varchar(40) NOT NULL,
commit_timestamp timestamp(0) NOT NULL,
"attributes" json NULL,
CONSTRAINT builds_pk PRIMARY KEY (id)
);
Configuring the jobs to always save artifacts
Builds may succeed or fail, but in any case, we want the logs to be saved for later processing. This applies to all build and simulation jobs.
build_yosys:
script: ...
artifacts:
paths:
- build/nextpnr-report.json
- ulx3s.bit
- "*.log"
when: always
Note that if an entry under paths fails refers to a non-existent file, GitLab Runner will complain a bit, but ultimately will go about its day, without triggering a job failure or skipping the remaining artifacts.
Collecting the results
The first custom job is tasked with collecting the results of all builds/tests, extracting key metrics, and storing them into the database.
For this reason, it needs to depend on all the previous jobs and their artifacts.
reports:
stage: upload
needs:
- job: build_ulx3s
artifacts: true
- job: test_cocotb
artifacts: true
- job: test_verilator
artifacts: true
when: always
image: python:3.10
script:
- pip install junitparser "psycopg>=3"
- ./tools/ci/save_build_stats.py
The body of this script is, for the most part, unremarkable. We begin by preparing a dictionary and collecting the first pieces of metadata:
results = {}
results["commit_title"] = os.environ["CI_COMMIT_TITLE"]
The results extraction is mostly tool specific, so I will only reproduce one example here, which is that of parsing Cocotb results in JUnit format:
if os.path.exists("results.xml"):
xml = JUnitXml.fromfile("results.xml")
failures = []
for suite in xml:
for case in suite:
# Failures are reported by a <failure /> node under the test case,
# while passing tests don't carry any result at all.
# To be determined whether this is the JUnit convention,
# or a cocotb idiosyncrasy.
if any(r._tag == "failure" for r in case.result):
failures.append(case.classname + ":" + case.name)
if len(failures) > 0:
results["sim"] = dict(result="fail", failed_testcases=failures)
else:
results["sim"] = dict(result="pass")
else:
results["sim"] = dict(result=None) # result unknown, maybe design failed to compile
Finally, we collect the indexable metadata and shove everything into the table:
with psycopg.connect(os.environ["POSTGRES_CONN_STRING"]) as conn:
cursor = conn.cursor()
cursor.execute('INSERT INTO builds(pipeline_timestamp, pipeline_url, branch, '
'commit_sha1, commit_timestamp, "attributes") '
'VALUES (%s, %s, %s, %s, %s, %s)', (
os.environ["CI_PIPELINE_CREATED_AT"],
os.environ["CI_PIPELINE_URL"],
os.environ["CI_COMMIT_BRANCH"],
os.environ["CI_COMMIT_SHA"],
os.environ["CI_COMMIT_TIMESTAMP"],
json.dumps(results))
)
The environment variable POSTGRES_CONN_STRING must be defined in the project’s CI settings. Normally your database host will provide the connection string readily. It should follow this template: postgresql://username:password@hostspec/dbname. Don’t forget to include the password!
Presentation
A second script takes care of fetching all historical records and presenting them on a webpage.
To deploy into GitLab pages the name of the job must be literally pages and it needs to upload a directory called public as artifact. Otherwise, the configuration is straightforward, it just needs to wait for the reports job to finish, in order to always work with the most up-to-date data.
pages:
stage: upload
needs: [reports]
image: python:3.10
script:
- mkdir public
- cd public
- pip install Jinja2 "psycopg>=3"
- ../tools/ci/present_build_stats.py
artifacts:
paths:
- public
The Python part starts by fetching all the DB records and passing them onto a Jinja template.
with psycopg.connect(os.environ["POSTGRES_CONN_STRING"]) as conn:
cursor = conn.cursor()
cursor.execute('SELECT id, pipeline_timestamp, pipeline_url, branch, commit_sha1, '
'commit_timestamp, "attributes" '
'FROM builds ORDER BY pipeline_timestamp DESC, id DESC')
builds = [dict(id=row[0],
pipeline_timestamp=row[1],
pipeline_url=row[2],
branch=row[3],
commit_sha1=row[4],
commit_timestamp=row[5],
**row[6] # unpack all other attributes into the dictionary
) for row in cursor.fetchall()]
env = jinja2.Environment(loader=jinja2.FileSystemLoader(os.path.dirname(__file__)))
template = env.get_template("build_stats.html")
Path("builds.html").write_text(template.render(
builds=builds,
project_url=os.environ["CI_PROJECT_URL"]
))
Here you can see the result live.
For more flavor, we also generate some badges. The idea here is to generate a publicly accessible JSON file that can be fed into shields.io Endpoint mode.
fmax_str = "%.1f MHz" % reference_build["build"]["fmax"][reference_clk]["achieved"]
Path("fmax.json").write_text(json.dumps(dict(schemaVersion=1,
label="Fmax",
message=fmax_str,
color="orange")))
# --> render via https://img.shields.io/endpoint?url=https://MY_GITLAB_PAGES.io/fmax.json
This produces a static URL that can be added to the project website and the image will always reflect the result of the most recent build: ![]()
Magic? No – science!
A note about security
The database connection string is supplied through an environment variable, which allows us to store it in the GitLab project with reasonable security – as long as an untrusted party cannot execute an echo command in our CI. Admittedly, this is a weakness of the chosen approach. To allow secure collection of results from pipelines triggered by third parties (which includes all merge requests, for example), it would probably require a separate, trusted pipeline or some kind of scraper task running somewhere in the cloud.
Scalability
You might have noticed that there is no pagination mechanism; in fact, the presentation job has O(n) complexity with respect to the number of historic builds. This will not scale once there are hundreds and thousands of builds, and a more efficient approach will be required.
The collection and presentation jobs also add some time to the overall runtime of the pipeline. Unfortunately, it seems that most of this time is just overhead of spinning the runner up, thus quite difficult to get rid of.
Final thoughs
At this point, it might seem an logical next step to generalize the presented solution into something more flexible, an off-the-shelf tool that could suit other teams. For now, I have decided against that for reasons of complexity. In the world of build automation and complex FPGA designs, different projects have wildly different needs; and while a couple hard-coded scripts are easy to understand and maintain, a useful generic framework would need a lot of flexibility, thus incurring a high upfront cost in terms of complexity.
Therefore, my recommendation would be that you just copy the code, and adapt it to your specific needs.
UPDATE (2023-11-01): Originally, the post recommended bit.io as the cloud Postgres database. Unfortunately, that service shut down earlier in 2023. Supabase seems like a competent alternative.